Giving AgentGateway a Semantic Brain with vLLM Semantic Router
· 阅读需 10 分钟


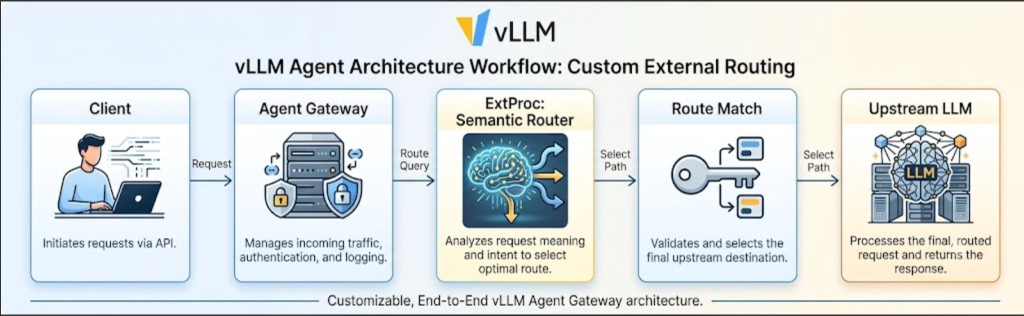
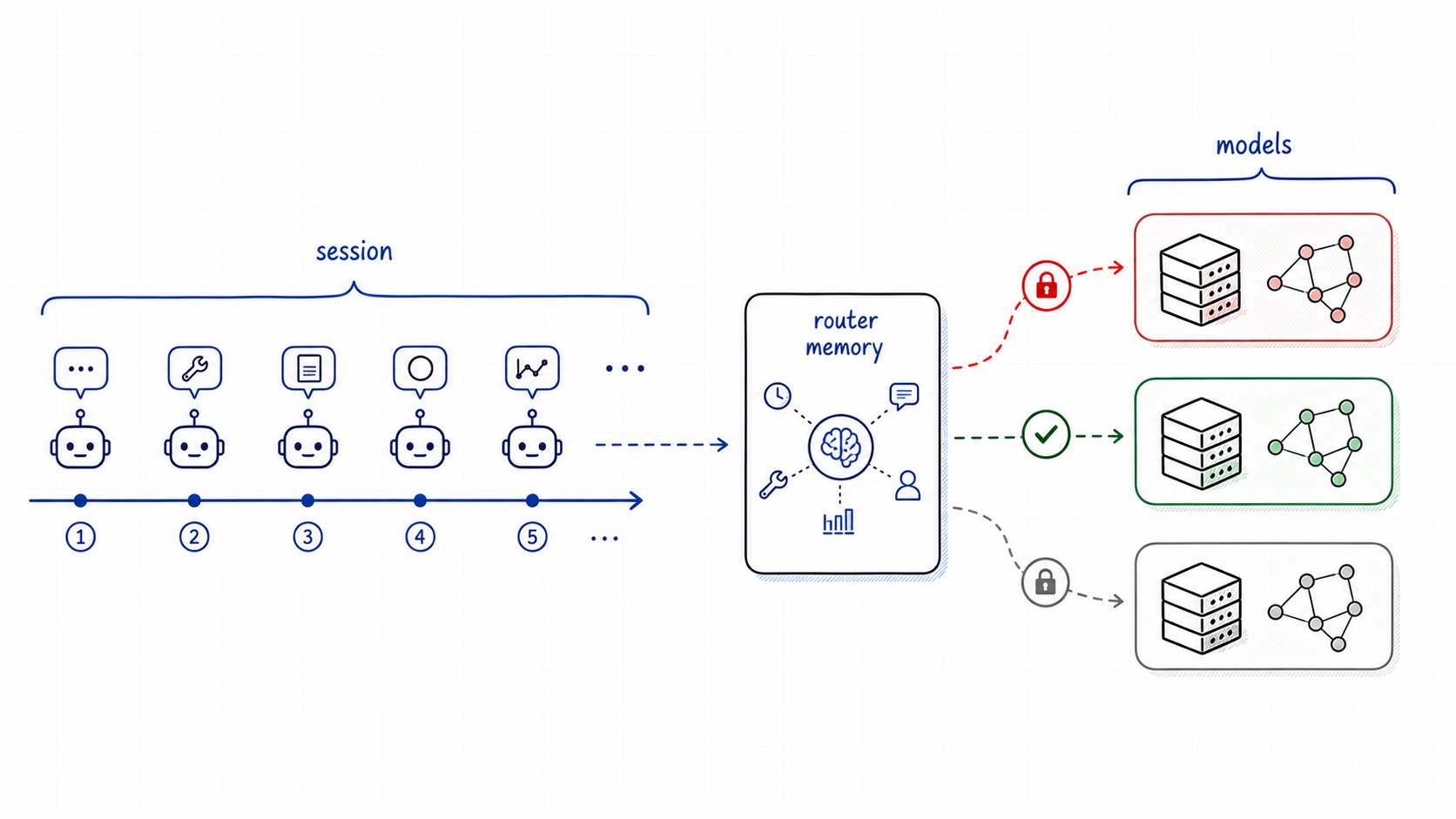
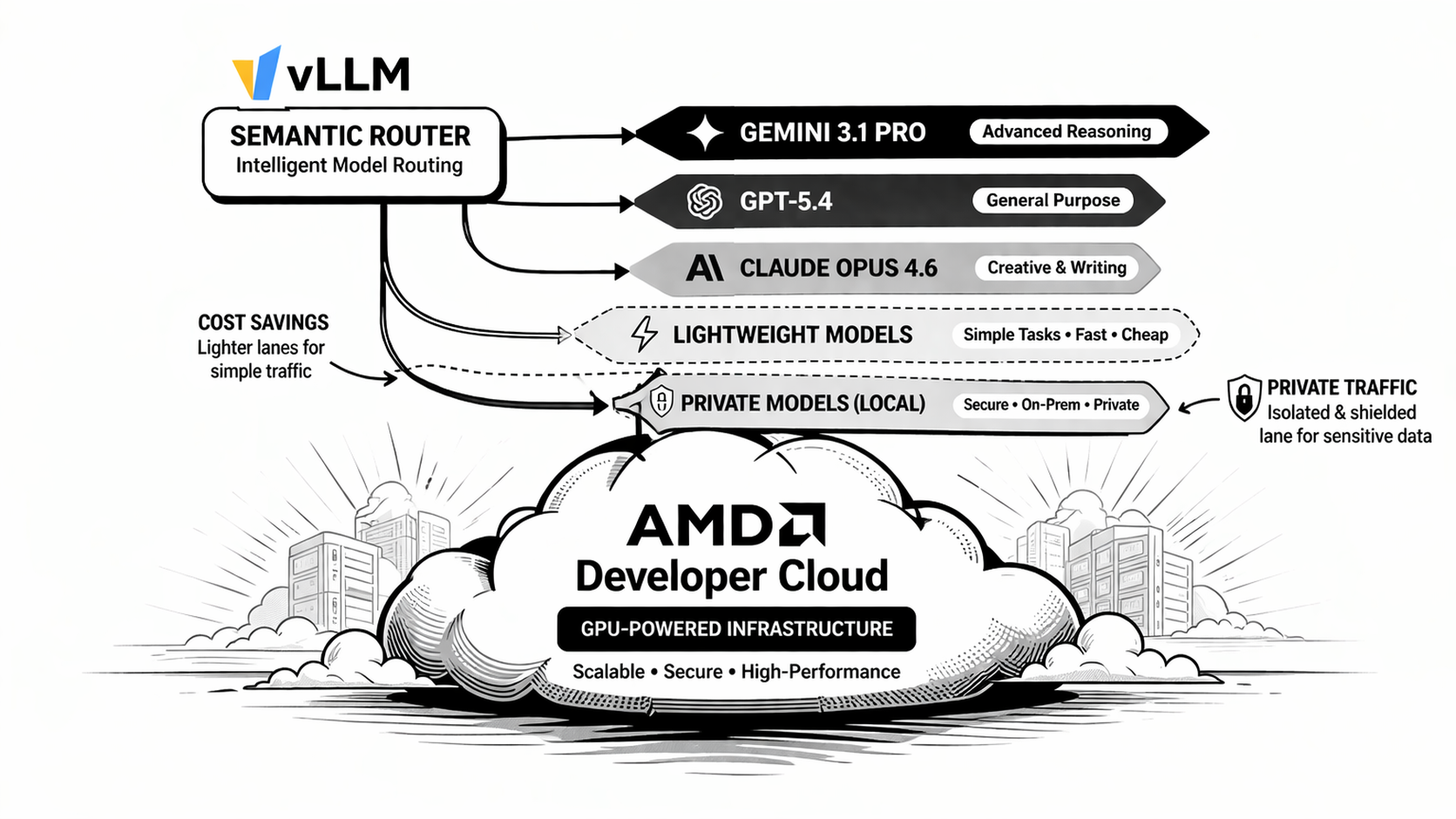
Agent systems that span multiple models — a local endpoint for coding, a frontier cloud model for deep reasoning, and a fast general-purpose model for everyday tasks — all face the same routing question: how should each request be directed to the right backend?
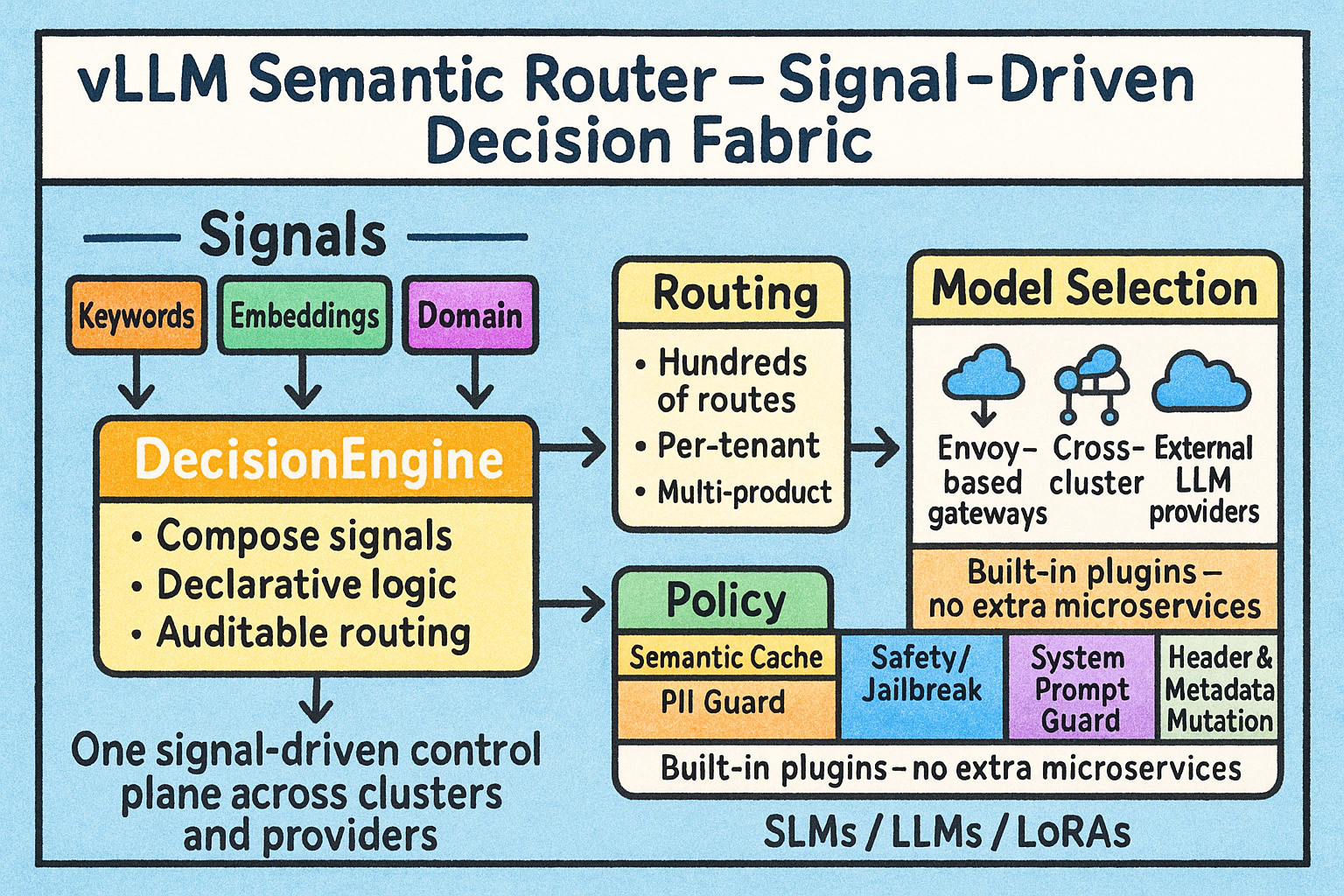
Many deployments start with a lightweight Python proxy or keyword matcher in front of the gateway. That approach works at small scale, but misroutes grow quickly as traffic, languages, and task types diversify. This post shows how vLLM Semantic Router running as an Envoy ExtProc sidecar inside AgentGateway replaces that pattern with semantic, config-driven routing.