Agentic Routing on AMD ROCm



Most agent systems start with a simple idea: call model: auto and let the
inference layer pick the right model. That is useful, but it is not enough for
long-running agents.
A coding agent can begin with architecture work, call tools, receive short tool outputs, continue with "fix that", then ask a privacy-sensitive question in the same user session. The latest message may look simple, but the route cannot be chosen from the latest message alone. The router also has to know whether this is a safe moment to switch models.
This guide shows how to deploy that pattern on AMD ROCm with vLLM Semantic Router. You will start one ROCm vLLM backend, serve the agentic routing recipe, open the dashboard, validate the OpenAI-compatible API, and use Inferoa to experience route decisions and Router Learning behavior from an agent client.
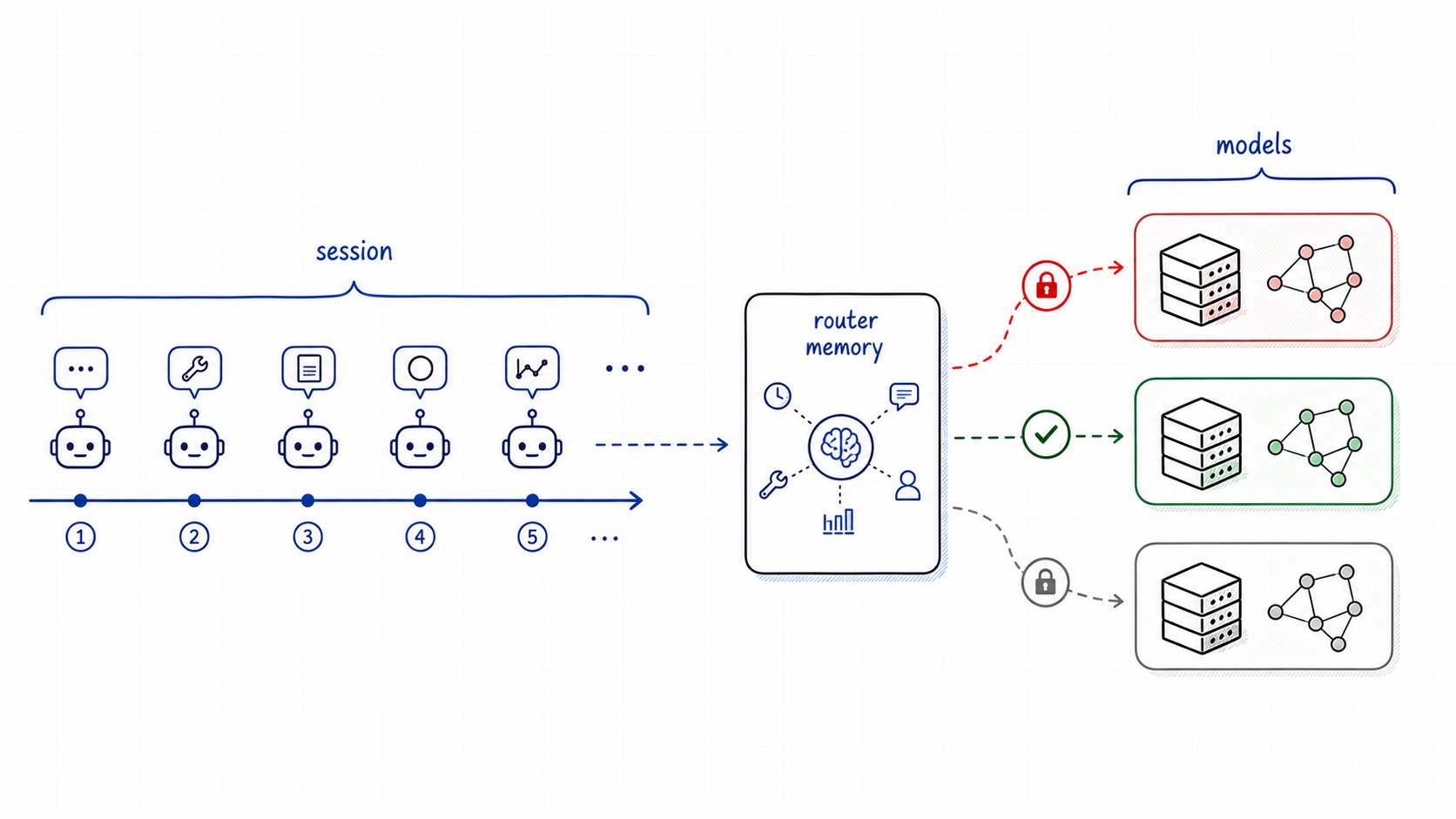
Agentic routing is not only choosing a model. It is choosing when to keep one.