Giving AgentGateway a Semantic Brain with vLLM Semantic Router


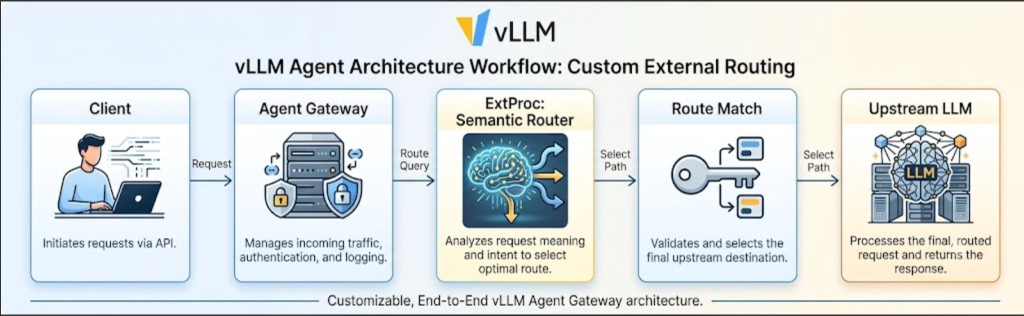
Agent systems that span multiple models — a local endpoint for coding, a frontier cloud model for deep reasoning, and a fast general-purpose model for everyday tasks — all face the same routing question: how should each request be directed to the right backend?
Many deployments start with a lightweight Python proxy or keyword matcher in front of the gateway. That approach works at small scale, but misroutes grow quickly as traffic, languages, and task types diversify. This post shows how vLLM Semantic Router running as an Envoy ExtProc sidecar inside AgentGateway replaces that pattern with semantic, config-driven routing.
The Problem: Keyword Routing Does Not Scale
A typical multi-model agent gateway fronts three backends:
| Backend | Model | Role |
|---|---|---|
| Local Ollama | qwen2.5-coder:7b | Coding and technical work |
| OpenAI | gpt-4o | Deep reasoning |
gemini-2.5-flash | Fast general tasks |
The routing layer was a simple keyword matcher:
# router.py — keyword-based routing
coding_keywords = ["code", "python", "javascript", "bash", "script",
"function", "bug", "error", "html", "css"]
reasoning_keywords = ["think", "analyze", "explain in detail",
"reasoning", "logic", "deduce"]
if any(k in prompt_lower for k in coding_keywords):
intent = "coding"
elif len(prompt) > 400 or any(k in prompt_lower for k in reasoning_keywords):
intent = "reasoning"
else:
intent = "simple"
After two weeks of sustained traffic, the rough numbers looked like this:
| Metric | With Python Router |
|---|---|
| Misrouted requests (spot-checked) | ~18% |
| Monthly estimated API cost | ~$24 |
| Routing latency (Python proxy hop) | ~45ms |
| Keyword list maintenance | Manual, weekly tweaks |
Eighteen percent misroutes is not just wasted spend — it produces worse answers. Scheduled agent jobs that sent "summarize this week's calendar and suggest optimizations" to the 7B local model instead of Gemini or GPT-4o returned noticeably weaker output. Mixed-language prompts and unanticipated domains silently fell through to the wrong lane.
The architecture needed a routing layer that understood the prompt, not just scanned it for keywords.
Enter vLLM Semantic Router + AgentGateway
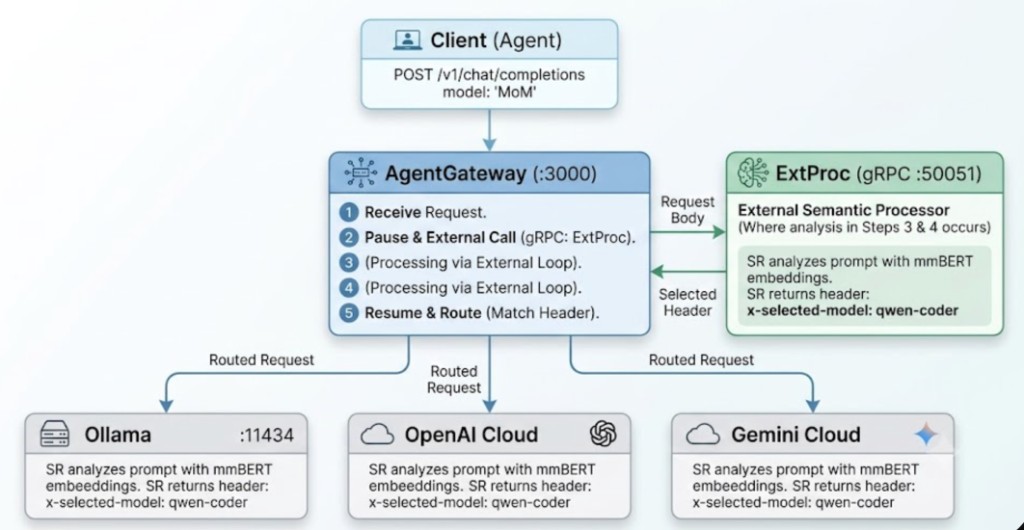
AgentGateway maintainers Keith Mattix and John Howard helped shape first-class ExtProc integration with vLLM Semantic Router. The resulting architecture is straightforward.
Instead of a Python reverse proxy sitting in front of the gateway, Semantic Router runs as an Envoy ExtProc sidecar. AgentGateway pauses the request, sends the HTTP body to the SR gRPC endpoint, receives a header mutation (x-selected-model: qwen-coder), and resumes routing. Zero proxy hops. Zero Python processes. Just gRPC-native intelligence inside the gateway's own request lifecycle.
Semantic Router uses an embedded mmBERT model (a 2D Matryoshka embedding model, ~130MB) to classify every prompt and compare it against model descriptions defined in YAML. No keyword lists. No regex. Actual embeddings.
For Kubernetes deployments, the same pattern is documented in the Install with agentgateway guide.
The Setup: Two YAML Files, No Code
The full integration is defined in two config files.
1. Semantic Router config (config.yaml)
This tells Semantic Router about the models and how to route between them:
version: v0.3
providers:
defaults:
default_model: qwen-coder
models:
- name: qwen-coder
provider_model_id: qwen2.5-coder:7b
api_format: openai
backend_refs:
- name: local-ollama
endpoint: host.docker.internal:11434
protocol: http
- name: gpt-4o
provider_model_id: gpt-4o
api_format: openai
backend_refs:
- name: openai-cloud
base_url: https://api.openai.com/v1
- name: gemini-flash
provider_model_id: gemini-2.5-flash
api_format: openai
backend_refs:
- name: gemini-cloud
base_url: https://generativelanguage.googleapis.com/v1beta/openai
routing:
modelCards:
- name: qwen-coder
param_size: 7B
context_window_size: 32768
description: >
Specialized coding model optimized for programming tasks.
Excellent at writing code, debugging, algorithms, data structures,
code review, refactoring, and technical implementation in Python,
Rust, JavaScript, Go. Best for code generation, fixing bugs,
writing tests, and technical programming Q&A.
- name: gpt-4o
param_size: 200B+
context_window_size: 128000
description: >
Frontier reasoning model with exceptional analytical capability.
Best for complex multi-step reasoning, strategic analysis,
comparing trade-offs, writing long-form essays, nuanced
explanations, math proofs, scientific reasoning.
- name: gemini-flash
param_size: ~100B
context_window_size: 1000000
description: >
Fast general-purpose model. Ideal for simple factual questions,
quick lookups, summarization, casual conversation, translations,
everyday tasks, and when speed matters more than depth.
decisions:
- name: MoM
description: "Mixture of Models router"
priority: 100
rules: {}
modelRefs:
- model: qwen-coder
- model: gpt-4o
- model: gemini-flash
algorithm:
type: multi_factor
multi_factor:
weights:
quality: 0.1
latency: 0.4
cost: 0.5
slo:
max_cost_per_1m: 0.5
The key insight: each model is described in natural language, and Semantic Router uses those descriptions as semantic anchors. When a new prompt arrives, the router embeds it and compares it against these descriptions using cosine similarity. The closest match wins.
2. AgentGateway config (agentgateway_config.yaml)
This tells AgentGateway to call Semantic Router as an ExtProc sidecar and route based on the header it sets:
policies:
- name:
name: semantic-router
namespace: default
target:
gateway:
gatewayName: default
phase: gateway
policy:
extProc:
host: "127.0.0.1:50051"
processingOptions:
requestBodyMode: buffered
responseBodyMode: none
requestHeaderMode: send
failureMode: failOpen
binds:
- port: 3000
listeners:
- routes:
- matches:
- headers:
- name: "x-selected-model"
value:
exact: "qwen-coder"
backends:
- ai:
provider:
openAI: {}
name: ollama
hostOverride: "localhost:11434"
- matches:
- headers:
- name: "x-selected-model"
value:
exact: "gpt-4o"
backends:
- ai:
provider:
openAI: {}
name: openai
policies:
backendAuth:
key: $OPENAI_API_KEY
- matches:
- headers:
- name: "x-selected-model"
value:
exact: "gemini-flash"
backends:
- ai:
provider:
gemini: {}
name: gemini
policies:
backendAuth:
key: $GEMINI_API_KEY
- backends:
- ai:
provider:
gemini: {}
name: gemini-default
policies:
backendAuth:
key: $GEMINI_API_KEY
Notice the separation of concerns: Semantic Router never touches API keys. It classifies the prompt and mutates a header. AgentGateway owns downstream auth. That is exactly how production gateways are designed — routing intelligence decoupled from security posture.
The failureMode: failOpen setting means if the SR container crashes or restarts, AgentGateway falls through to the default Gemini route. During SR container restarts, client requests still get answered without interruption.
ARM64 on Apple Silicon: Two Bugs, Two PRs
On ARM64 hosts (including Apple Silicon), the SR container may start while embeddings remain unavailable:
{
"msg": "embedding_models_init_completed",
"embedding_ready": false,
"tools_ready": false
}
The mmBERT model loaded but the embedding runtime never became ready. Every routing attempt logged:
Failed to embed model qwen-coder: failed to generate batched embedding (status: -1)
Bug #1: Wrong FFI dispatch (#2172)
The Go router was calling candle_binding.GetEmbeddingBatched() for all model types — but the Rust FFI backend only supports batched embeddings for qwen3 architectures. For mmbert (the default), it returned status: -1.
The fix in PR #2192 adds a dispatch check:
// Only qwen3 supports the batched FFI. Others use single-text FFI.
func candleEmbeddingSupportsBatched(modelType string) bool {
return modelType == "qwen3"
}
For non-qwen3 models, it gracefully falls back to GetEmbeddingWithModelType(), which works on ARM64.
Bug #2: Missing model files on first boot (#2173)
On first boot, when the SR container downloaded mmBERT model files from HuggingFace, several required files (like tokenizer.json and config.json) were not being fetched. Fixed in PR #2195.
Both issues were triaged and fixed within days by the vLLM Semantic Router team — particularly @WUKUNTAI-0211 for the FFI dispatch fix and @theohsiung for the file completeness fix. On ARM64/Apple Silicon, pull the latest main and routing works as expected.
Proof: Real Routing Logs
Send a coding prompt:
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "MoM",
"messages": [
{"role": "user", "content": "Write me a Python function to compute fibonacci numbers using memoization"}
]
}'
Step 1 — Semantic Router classifies the prompt (1ms):
{
"msg": "routing_decision",
"original_model": "MoM",
"selected_model": "qwen-coder",
"reason_code": "auto_routing",
"routing_latency_ms": 1,
"component": "extproc"
}
Step 2 — AgentGateway routes to Ollama:
info request
gateway=default/default
route=default/route0
endpoint=localhost:11434
http.status=200
gen_ai.request.model=qwen2.5-coder:7b
gen_ai.response.model=qwen2.5-coder:7b
gen_ai.usage.input_tokens=41
gen_ai.usage.output_tokens=366
duration=22537ms
One millisecond of routing overhead. The rest is upstream generation time.
On container boot, the full pipeline appears in the logs:
{"msg":"embedding_models_init_started","mmbert_configured":true,"use_cpu":true}
{"msg":"embedding_models_initialized","use_batched":false}
{"msg":"selection_factory_initialized","selector_count":14}
{"msg":"startup_complete","embedding_ready":true,"sem_cache_enabled":true,
"model_selection":true,"extproc_port":50051,"decisions":"MoM"}
Fourteen selection algorithms are registered out of the box — multi-factor, ELO, RL-driven, hybrid, latency-aware, session-aware, KNN, SVM, K-means, and more. The reference configuration uses multi_factor with cost-heavy weighting, but switching algorithms is a single YAML change.
Measured Results
| Metric | Python Router | vLLM Semantic Router |
|---|---|---|
| Misrouted requests | ~18% | ~3% (subjective spot-checks) |
| Routing latency | ~45ms (HTTP proxy) | 1–3ms (gRPC ExtProc) |
| Monthly estimated API cost | ~$24 | ~$14 |
| Maintenance effort | Weekly keyword updates | Zero (model descriptions are stable) |
| Failover behavior | Manual restart | Automatic failOpen to Gemini |
| Language support | English keywords only | Multi-language (embedding-based) |
| Config | 100 lines of Python | 2 YAML files |
The cost savings come from fewer misroutes. When "explain the async/await pattern in Rust" correctly goes to local Ollama instead of GPT-4o, that is a $0.003 request instead of $0.03. Across hundreds of daily agent requests, the difference adds up quickly.
Why Agent Builders Should Care
Whether the deployment runs on a single host or a production fleet in Kubernetes, agents benefit from a routing layer that understands prompts:
-
Cost control is the primary agent problem. Agents generate a lot of requests. Without intelligent routing, every request goes to the most expensive model. Semantic Router's
multi_factoralgorithm explicitly weighs cost, latency, and quality. -
Keyword routing does not scale. The moment an agent handles a domain that was not anticipated, keyword-based routing silently fails.
-
AgentGateway + Semantic Router is production-grade. AgentGateway is a Gateway API data plane built in Rust. Semantic Router is an Envoy ExtProc server written in Go and Rust, backed by the vLLM project. This is the same architecture used in Kubernetes clusters with dozens of models.
-
Zero code maintenance. Once model descriptions are written, the routing config stays stable. Semantic Router learns from the descriptions, not from rules that require ongoing updates.
What's Next
Common follow-on work for this architecture includes:
- Observability — wiring Jaeger and Prometheus to trace every request from client → AgentGateway → Semantic Router → upstream LLM. AgentGateway already emits OpenTelemetry-compatible spans.
- More models — adding specialized models (medical, legal) with just a new model card in YAML. Semantic Router figures out when to use them.
AgentGateway plus vLLM Semantic Router turns a keyword-based proxy into an ML-powered routing plane — with the same ExtProc pattern usable from a single-node setup to a multi-model Kubernetes deployment.
Get Started
- Install with agentgateway — Kubernetes integration guide
- Gateway API Inference Extension with agentgateway — route to InferencePools with header-based selection
- Multi-factor selection algorithm — cost, latency, and quality weighting
- Community write-up on DEV — extended narrative by Anup Sharma
Have a community story about Semantic Router? Open an issue like #2257 and the team will help get it published.